


摘要
從大模型技術發展趨勢出發,分析了多模態、長序列和混合專家模型的架構特征和算力需求特點。圍繞大模型對巨量算力規模與復雜通信模式的需求,重點從算力利用效率、集群互聯技術兩方面量化分析了當前大模型算力基礎設施存在的發展問題和面臨的技術挑戰,并提出了以應用為導向、以系統為核心、以效率為目標的高質量算力基礎設施發展路徑。
關鍵詞:多模態模型;長序列模型;混合專家模型;算力利用效率;集群互聯;高質量算力
引言
近年來,生成式人工智能技術,尤其是大語言模型(Large Language Model,LLM)的快速發展,標志著人工智能進入了一個前所未有的新時代。模型能力的提升和架構的演進催生了新的算力應用范式,對所需的算力基礎設施提出了全新的挑戰。
1、大模型技術發展趨勢
1.1 大語言模型
最初的語言模型主要基于簡單的統計方法,隨著深度學習技術的進步,模型架構逐步從循環神經網絡(Recurrent Neural Network,RNN)到長短期記憶(Long Short Term Memory,LSTM)再到Transformer演進,模型的復雜性和能力相繼提升。2017年,Ashish Vaswani等首先提出了Transformer架構,這一架構很快成為了大語言模型開發的基石。2018年,BERT通過預訓練加微調的方式,在多項自然語言處理任務上取得了前所未有的成效,極大地推動了下游任務的發展和應用。2018—2020年,OpenAI相繼發布了GPT-1、GPT-2和GPT-3,模型的參數量從1 億級別增長到1 000 億級別,在多項自然語言處理任務上的性能呈現近似指數級的提升,論證了尺度定律(Scaling Law)在實際應用中的效果。2022年底,ChatGPT發布之后,引發了一輪LLM熱潮,全球諸多企業、研究機構短時間內開發出LLaMA、文心一言、通義千問等上百種大語言模型。這一時期的模型大都基于Transformer基礎架構,利用大量的文本數據進行訓練,通過學習大規模數據集中的模式和關系,能夠執行多種語言任務。但是,LLM的發展很快遇到了兩個顯著的問題,一是模型的能力局限于對文本信息的理解和生成,實際的落地應用場景受限;二是稠密模型架構特征將會使得模型能力提升必然伴隨著算力需求的指數級增加,在算力資源受限的大背景下模型能力進化的速度受限。
1.2 多模態模型
為了進一步提升大模型的通用能力,研究者開始探索模型在非文本數據(如圖像、視頻、音頻等領域)中的應用,進而發展出了多模態模型。這類模型能夠處理和理解多種類型的輸入數據,實現跨模態的信息理解和生成。例如,OpenAI的GPT-4V模型可以理解圖片信息,而Google的BERT模型則被擴展到VideoBERT用于理解視頻內容。多模態模型的出現大大擴展了人工智能的感知能力和應用范圍,從簡單的文本處理到復雜的視覺和聲音處理。多模態模型在基礎模型架構上跟LLM一樣大都采用Transformer,但是通常需要設計特定的架構來處理不同類型的輸入數據。例如,它們可能結合了專門處理圖像數據的卷積神經網絡(Convolutional Neural Networks,CNN)組件,需要使用跨模態的注意力機制、聯合嵌入空間或特殊的融合層來實現對來自不同模態信息的有效融合。
1.3 長序列模型
研究者們發現通過擴展上下文窗口可以讓大模型能夠更好地捕捉全局信息,有助于更準確地保留原文的語義、降低幻覺的發生、提高新任務的泛化能力,這就是提升大模型能力的另外一條有效的路徑——長序列(Long Sequence)。2023年以來,主流大模型都在不斷提高長序列的處理能力(見圖1),比如GPT-4 Turbo可以處理長達128 K的上下文,相比較GPT-3.5的4K處理能力已經增長了32倍,Anthropic的Claude2具備支持200 K上下文的潛力,Moonshot AI的Kimi Chat更是將中文文本處理能力提高到了2 000 K。從模型架構上來看,傳統的LLM訓練主要對Transformer中耗時最多的兩個核心單元——多頭注意力層(Multi-Head Attention,MHA)和前饋神經網絡層(Feedforward Neural Network,FNN)進行張量并行,但保留了歸一化層和丟棄層,這部分元素不需要大量的計算但隨著序列的長度增加會產生大量的激活值內存。由于這部分非張量并行的操作沿著序列維度是相互獨立的,可以通過沿序列維度切分實現激活值內存的減少。然而,序列并行(Sequence Parallelism,SP)的增加會引入額外的全聚集(All Gather)通信操作。因此,長序列的訓練和推理會使得計算復雜度和難度提升,計算復雜度隨序列長度n呈平方增加O(n2),模型需要引入新的并行層次和集合通信操作,從而導致端到端通信耗時占比增加,將會對模型算力利用率(Model FLOPS Utilization,MFU)產生影響。
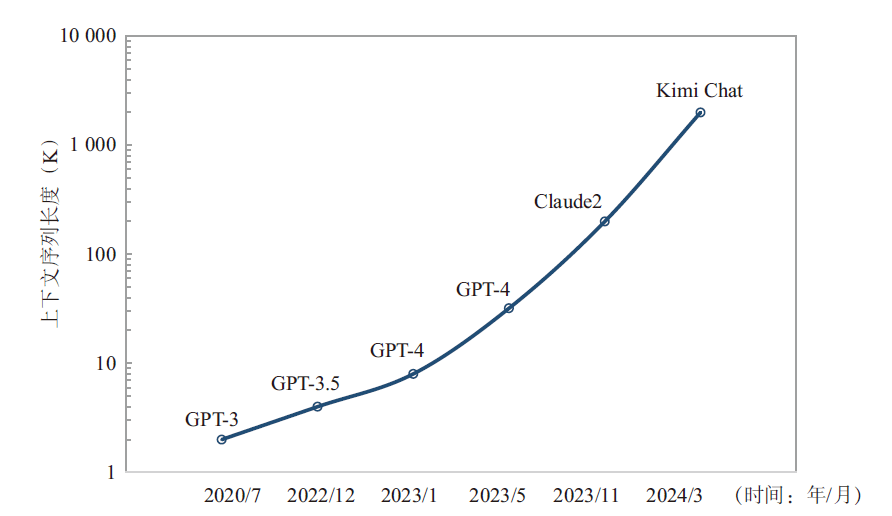
圖1 大模型上下文序列長度發展趨勢
1.4 混合專家模型
為了在提高模型能力的同時能夠優化算力開銷,研究者們選擇引入條件計算機制,即根據輸入有選擇地激活部分參數來進行訓練,這樣就使得整體計算開銷隨模型參數量的增長趨勢相對變緩,這就是混合專家(Mixture of Experts,MoE)模型的核心思想。MoE模型實際構建了一種稀疏型的模型組件,將大型網絡分解為若干個“專家”子網絡,每個專家擅長處理特定類型的信息或任務,通過一個門控網絡,在給定輸入時動態選拔最適合的專家參與計算,這樣既可以減少不必要的計算量,也能提高模型的專業性和效率。Google早在2022年就發布了具有1.6 億參數的MoE模型Switch Transformer,包含2 048個專家,在同樣的FLOPS/Token的計算量下,Switch Transformer模型相比稠密型的T5-Base模型訓練性能有7倍的提升。
MoE模型通過這種方式,在保持模型性能的同時,相比同等規模的稠密模型顯著降低了計算資源的需求,在處理大規模數據和任務時表現出了更高的效率和可擴展性。如今MoE模型已經成為了業界大模型的發展趨勢,2024年3月以來,已經先后出現了GPT4、Mixtral-8×7B、LLaMA-MoE、Grok-1、Qwen1.5-MoE、Jamba等10余種MoE模型。但是,MoE模型層的引入同時也帶來了額外的通信開銷,相比較LLM訓練過程常用的張量并行、流水線并行和數據并行之外,MoE模型的訓練引入了一種新的并行策略——專家并行(Expert Parallelism,EP),需要在MoE模型層前后分別增加一次多對多(All-to-All)通信操作,由此帶來了對硬件互聯拓撲和通信帶寬的更高要求。
根據上述分析,多模態、長序列、MoE模型已經成為大模型架構演進的確定性趨勢,其中多模態、長序列模型側重在模型能力側的提升,MoE模型兼顧模型能力的提升和算力利用效率的優化。這種發展不僅提升了人工智能在內容理解和內容生成方面的能力,而且提高了模型的泛化能力和任務適應性。然而,模型架構的演進同時帶來了更巨量的算力需求以及更復雜的集合通信需求,對現有算力基礎設施帶來了更大挑戰。
2、大模型算力基礎設施發展問題與挑戰
2.1 可用算力規模亟需算力利用效率提升
業界先進的(State-Of-The-Art,SOTA)模型參數規模和數據規模仍在持續增長,巨頭之爭已經從千億模型向萬億模型發展(見圖2),GPT-4模型具有1.8萬億參數,在約 13萬億個Token上進行了訓練,算力需求大約為2.15e25 FLOPS,相當于在大約2.5萬張A100加速卡上運行90~100天。為此,領先的科技公司正在加速算力基礎設施建設,Meta在原有1.6萬張A100卡集群基礎上又建設兩個具有約2.5萬張H100加速卡集群,用來加速LLaMA3的訓練;Google建設了具有2.6萬張H100加速卡的A3人工智能超級計算機,可以提供26 ExaFLOPS的人工智能性能,Microsoft和OpenAI正在為GPT-6訓練構建具有10萬張H100加速卡集群,并規劃具有數百萬張卡的“星際之門”人工智能超算。由此可見,萬卡已經成為未來先進大模型訓練的新起點。
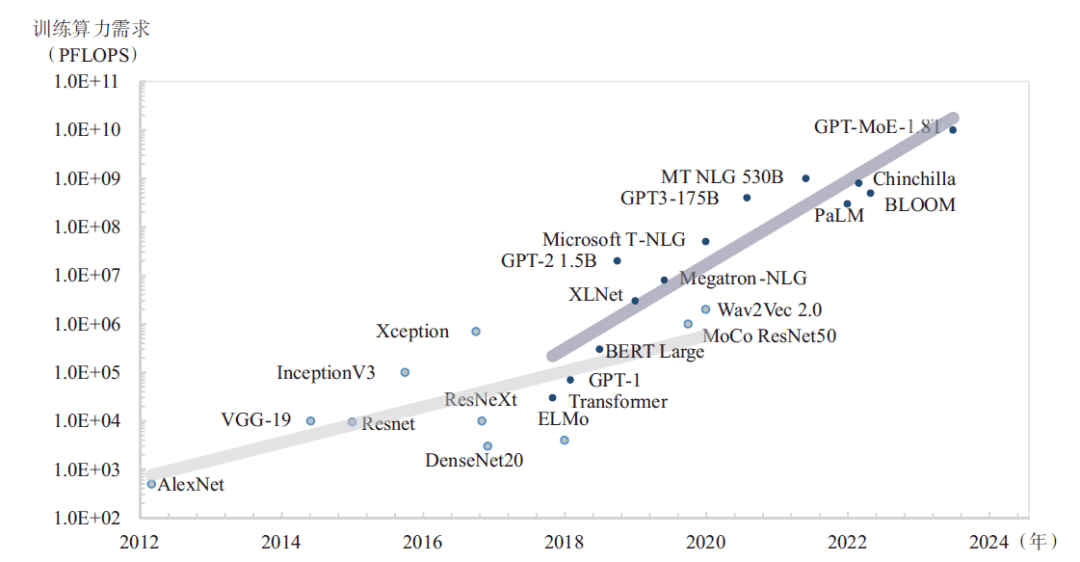
圖2 大模型算力需求發展趨勢
隨著算力需求持續增加、算力規模持續擴大,算力利用效率問題日益凸顯。據公開報道,GPT-4訓練的MFU在32%~36%之間,其根本原因是顯存帶寬限制了芯片算力的發揮,即“內存墻”(Memory Wall)問題。在LLM模型的訓練過程中,模型參數、梯度、中間狀態、激活值都需要存放在顯存當中,并且需要頻繁地傳輸參數和梯度信息以進行參數的更新。高顯存帶寬可以加快參數和梯度數據的傳輸速度,從而提高參數更新的效率,加速模型收斂的速度。因此,用于人工智能訓練的高端加速卡會選用最先進的高帶寬內存(High Bandwidth Memory,HBM)作為顯存,以求最大化數據傳輸速度,增加計算時間占比,從而獲得更高的算力利用效率。
從宏觀技術發展趨勢上看,在過去20年間芯片的算力峰值以每2年3倍的速度增長,但是內存的帶寬增長速度只有1.6倍[11]。內存的性能提升速度遠低于處理器的性能提升速度,這就使得芯片計算力和運載力之間的剪刀差越來越大,僅通過增加處理器數量和核心數,也無法有效提高整體的計算能力。為此,NVIDIA從V100開始,在每一代芯片中間都會有一次顯存升級,以A100為例,首發版本采用40 G HBM2顯存,帶寬最高1 555 GB/s,升級版本采用80 G HBM2,帶寬提升至2 039 GB/s,但這帶來的算力利用效率和應用性能提升效果有限,A100 80 G在Bert-Large微調場景下性能提升僅14%(見圖3)。
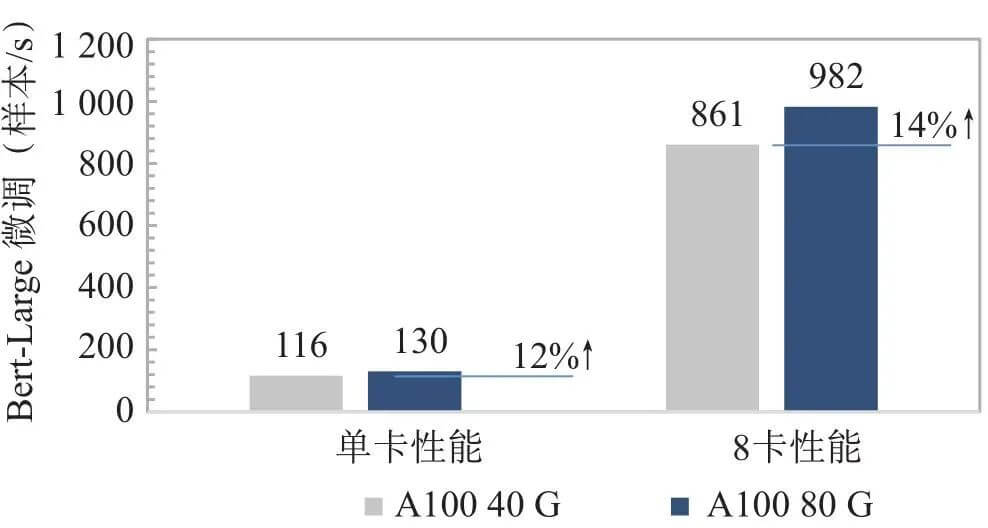
圖3 相同算力下不同顯存帶寬A100模型性能對比
為了能夠量化顯存帶寬對芯片算力利用效率的影響,采用具有相同顯存(容量96 G、帶寬2.45 TB/s)、不同算力的人工智能加速卡,在具有不同參數規模大小的LLM模型預訓練場景中進行了算力效率的實測。如圖4(a)所示,在使用BF16算力精度訓練LLaMA-7B模型的過程中,BF16算力利用率隨芯片算力的降低而顯著增加,對于具有443 TFLOPS算力值的芯片而言,其算力利用率只有54%,而具有148 TFLOPS算力的芯片,算力利用率達到了71.3%,這意味著顯存帶寬限制了高算力芯片的算力利用效率。同樣的規律也反映在了LLaMA-13B和GPT-22B等更大參數規模的模型預訓練實測結果中。如圖4(b)所示,當標稱BF16性能從148 TFLOPS增加到298 TFLOPS,即標稱算力增加2倍的情況下,可用算力增加僅1.8倍,或者說算力損失29.6%;當BF16性能進一步從298 TFLOPS繼續增加到443 TFLOPS,即標稱算力增加48.8%的情況下,可用算力性能僅增加22.4%,算力損失高達42.1%。由此可以推斷,算力性能進一步提高所帶來的可用算力收益會由于顯存帶寬的限制呈現邊際遞減,即GPT-4訓練的MFU只有不到40%的原因。可以看出,“內存墻”是限制當前可用AI算力擴展的最大瓶頸。
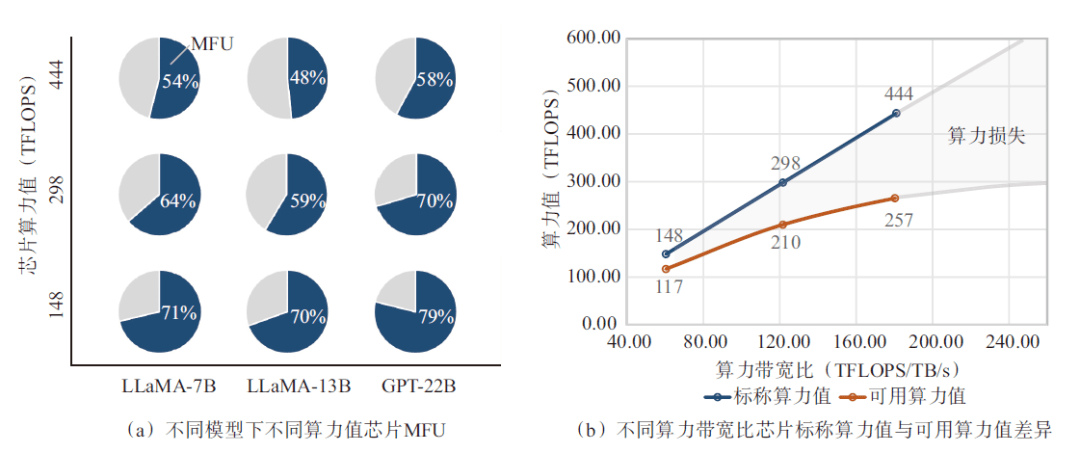
圖4 顯存帶寬對算力利用效率影響
2.2 集群性能提升依賴跨尺度、多層次互聯
在尺度定律的驅動下,SOTA模型的參數量以每2年410倍的速度增長、算力需求以每2年750倍的速度增長,遵循“摩爾定律”的硬件算力增長速度和顯存容量增長速度遠遠無法滿足模型訓練的需求。因此,構建多芯互聯集群成為大模型技術發展的必經之路,能夠支持SOTA模型訓練集群的規模也在短時間內從千卡向萬卡發展,集群性能的實現將會受到顯存帶寬、卡間互聯帶寬、節點間互聯帶寬、互聯拓撲、網絡架構、通信庫設計、軟件和算法等多重因素影響,大規模加速計算集群的構建已經演變成為跨尺度、多層次的復雜系統工程問題。
從應用層面來看,大模型訓練往往需要通過有機的組合多種分布式策略,來有效地緩解LLM訓練過程中的硬件限制。對于基于Transformer架構的模型來說,常用的分布式策略包括數據并行、張量并行和流水線并行,各自的實現方式和所引入的集合通信操作有所不同。其中,數據并行和流水線并行的通信計算比不高,通常發生在計算節點之間。張量并行的核心思想是對Transformer Block中的兩個核心單元——多頭自注意力層和前饋神經網絡層進行拆分,其中多頭自注意力層按照不同的頭進行并行拆分,而前饋神經網絡層按照權重進行并行拆分。使用張量并行時,每個Transformer Block將在前向計算和反向傳播時分別引入兩次額外的All Reduce通信操作。與數據并行相比,張量并行具有更高的通信計算比,這意味著張量并行算法對計算設備間的通信帶寬需求更高。因此,在實際應用中,一般把張量并行算法限制在單個計算節點內。如前文所述,隨著大模型進一步向多模態、長序列、混合專家架構演進,分布式策略也隨之更加復雜,序列并行和專家并行的引入,也帶來了更多All Gather和All-to-All通信操作,與張量并行類似,需要計算設備間超低延遲、超高帶寬的通信能力,從而進一步提高對單個計算節點或者說計算域的性能要求。
從硬件層面來看,互聯的設計一方面需要滿足算力高效擴展的需求,另一方面還要匹配并行訓練集合通信對互聯拓撲的要求。互聯設計可以按尺度分為片上互聯、片間互聯和節點間互聯。片上互聯物理尺度最小、技術難度較高,需要采用芯粒(Chiplet)技術將多個Chiplet進行合封并建立超高速互聯鏈路,領先的芯片廠商AMD、Intel、NVIDIA、壁仞科技等公司的產品都采用相關技術。以NVIDIA的B100芯片為例,由于逼近光刻工藝極限,芯片單位面積計算能力較上代只有14%提升,性能的進一步提升只能通過增加硅面積,但這又受到掩膜極限的限制。于是,NVIDIA在盡可能做大單晶粒面積的基礎上,通過更先進的基片上芯片(Chip on Wafer on Substrate,CoWoS)工藝將兩個晶粒整合到一個封裝當中,之間通過10 TB/s NVLink進行互聯,使得兩個芯片可以作為一個統一計算設備架構(Compute Unified Device Architecture,CUDA)在GPU運行。由此可見,在當前工藝極限和掩膜極限下,通過先進封裝和高速晶粒對晶粒互聯可以進一步推動芯片性能提高,但是這條技術路線的封裝良率和高昂成本也將會極大限制最新芯片的產能,影響芯片的可獲得性。
相比片上互聯,片間互聯的技術成熟度更高、可獲得性更優,通常這部分互聯發生在單一節點或超節點內部,旨在構建多卡之間超高帶寬、超低延遲的計算域,來滿足張量并行、專家并行和序列并行極高的通信需求。目前,已經有NVLink、PCIe、RoCE(RDMA over Converged Ethernet)以及諸多私有互聯方案。從互聯速率來看,NVIDIA第5代NVLink單Link雙向帶寬從第4代NVLink的50 GB/s升級到100 GB/s,也就是說B100/B200片間互聯雙向帶寬最高可以達到1 800 GB/s,AMD的Infinity Fabric最大可以支持112 GB/s 點對點(Peer-to-Peer,P2P)互聯帶寬。從互聯拓撲形態來看,片間互聯可以分為直連拓撲和交換拓撲兩大類,直連拓撲的通用性更強、協議兼容性更高,如AMD MI300X、Intel Gaudi、寒武紀MLU系列等開放加速規范模組(OCP Accelerator Module,OAM)形態加速卡可以通過通用加速器基板(Universal Baseboard,UBB)實現8卡全互聯,NVIDIA H100 NVL、AMD MI210、Intel Gaudi3(HL-338)等PCIe形態加速卡則可以通過橋接器實現2卡或4卡互聯,直連拓撲的問題在于片間互聯均分每卡的輸入/輸出(Input/Output,I/O)總帶寬,導致任意兩卡間P2P互聯帶寬較低,互聯帶寬的提升依賴于SerDes速率的升級,相較算力提升速度滯后。交換拓撲需要基于交換機(Switch)交換芯片,目前主流芯片廠商中只有NVIDIA提供基于NVSwitch的互聯方案,所有GPU的縱向擴展(Scale-up)端口直連到NVSwitch以實現全帶寬、All to All互聯形態,這也是NVLink帶寬遠高于直連拓撲方案的原因。未來,隨著單卡算力的提升以及單節點內加速卡數量提升,基于Switch芯片構建更高帶寬、更大規模的GPU互聯域將成為一種趨勢,但是如何實現Scale-up網絡的延遲優化、擁塞控制、負載均衡以及在網計算也將成為新的挑戰。
節點間橫向擴展(Scale-out)互聯作用主要是為參數面網絡中流水線并行和數據并行提供足夠通信帶寬,通常采用Infiniband或RoCE組成胖樹(Fat-Tree)無阻塞網絡架構,二者都能夠通過多層組網實現千卡乃至萬卡級集群互聯,比如采用64端口交換機,通過3層Fat-Tree無阻塞組網理論上可以構建約6.6萬卡集群,采用128端口交換機理論上可以構建約52.4萬卡集群。從節點側來看,Scale-out的設計分為外置網絡控制器和集成網絡控制器兩種類型,外置網絡控制器方案通用性更強,PCIe標準形態的網絡控制器通常會按1∶1或者1∶2的比例與加速卡連接到同一顆PCIe Switch芯片上以實現最短的Scale-out路徑,可以根據現有數據中心網絡基礎設施設計來靈活選擇與之相匹配的網絡控制器類型和數量組成遠程直接內存訪問(Remote Direct Memory Access,RDMA)網絡方案,支持Infiniband卡、以太網卡以及定制智能網卡。集成網絡控制器方案將網絡控制器直接集成到加速卡芯片當中,比較有代表性的如Intel Gaudi系列,Gaudi2每顆芯片支持直出300 Gbit/s Ethernet Scale-out鏈路,Gaudi3將帶寬進行了翻倍升級達到600 Gbit/s,計算和網絡的同步在芯片內完成,無需主機干預,可以進一步減小延遲。數據中心內部的節點間互聯方案已經相對成熟,但隨著GPU集群建設規模的不斷擴大,節點間互聯方案的成本和能耗也在不斷提升,在中等規模集群當中占比已達15%~20%。因此,需要面向實際應用需求,平衡性能、成本、能耗三大要素,最終實現全局最優的節點間互聯方案設計。此外,大模型頭部公司正在規劃的具有百萬卡級的集群,已經超出現有網絡架構可擴展極限,而單一數據中心無法同時為如此規模的卡提供足夠的電力支撐。未來,超大規模跨域無損算力網絡將會是支撐更大規模模型訓練的關鍵。
綜上,隨著大模型算力需求的增長,加速集群互聯技術已經演變成為跨尺度、多層次的復雜系統工程問題,涉及芯片設計、先進封裝、高速電路、互聯拓撲、網絡架構、傳輸技術等多學科和工程領域,需要以系統為核心,自上而下軟硬協同設計才能獲得最優的集群性能。
3、大模型算力基礎設施高質量發展路徑
隨著SOTA大模型訓練算力起點從千卡向萬卡乃至更大規模演進,能源逐漸成為大模型發展遇到的主要瓶頸,在算力資源和電力資源的雙重限制下,未來大模型的軍備競賽將會從“算力之爭”演變為“效率之爭”,優化算力供給結構,發展具有高算效、高能效、可持續、可獲得、可評估五大特征的高質量算力已經成為當務之急。
算力效率的提升要圍繞算力的生產、聚合、調度、釋放形成一個完整的技術體系。在算力生產環節,算力和顯存帶寬的設計失衡往往是導致算力效率損失的主要因素。因此,芯片“算力-顯存”協同設計至關重要,需要以算力效率為目標來平衡芯片的計算能力和顯存的運載能力,避免顯存帶寬約束下的巨大算力損失。在算力聚合環節,通過“算力-互聯”協同設計和“算力-網絡”協同設計,采用高、低速域分層互聯架構,為芯片匹配合適的片間互聯和節點間互聯帶寬,解決通信性能瓶頸,可以進一步提升芯片在實際業務模型下的MFU,提升集群層面投資回報率。在算力調度環節,通過全面的監控指標和異常檢測快速定位軟硬件故障,通過斷點續訓、故障容錯等機制快速恢復訓練,實現大模型長時間穩定訓練,以此提升集群算力整體利用率,降低大模型整體訓練成本。在算力釋放環節,兼容主流生態,支持業界主流框架、算法和計算精度,能夠在最短時間內利用最新的精度優化、顯存優化以及通信優化上的算法創新成果發掘出有限算力的最大價值。
能源利用效率的提升需要以節能為目標,開展面向應用、軟硬協同的集群方案設計,在高算效服務器系統硬件基礎上,通過匹配實際可用算力規模的網絡方案實現設計層面的集群功耗優化。進一步,通過部件、系統、機柜、數據中心多層級先進液冷技術的應用,結合供電、散熱、制冷、管理一體化設計實現部署層面的能效提升,最終獲得全局最優電源使用效率(Power Usage Effectiveness,PUE)。
此外,大模型算力基礎設施已經成為推動信息產業核心技術發展的重要驅動力,需要聚攏核心部件、專用芯片、電子元器件、基礎軟件、應用軟件等國內外產業鏈領先技術方案,加速構建分層解耦、多元開放、標準統一的產業鏈生態,降低對單一技術路線的依賴、避免煙囪式發展,通過產業鏈協同創新實現可持續算力演進和算力產業的健康發展。持續推動算力基建化,采用融合架構,通過硬件重構實現多元異構算力資源池化,提供多元、彈性、可伸縮擴展的算力聚合能力,通過軟件定義實現資源池的智能高效管理,提供更高效、更便捷的算力調度能力,降低多元算力的使用門檻,實現算力普適普惠。最后,還需要建立以應用為導向、以效率為目標、全面科學的高質量算力評估標準,推動算力供給結構優化,促進算力產業良性發展。
?結束語
在市場、資本、政策的聯合驅動下,大模型快速向多模態、長序列、混合專家形態演進,參數量更加龐大、模型架構日益復雜,從而帶來對更大規模算力和更復雜通信模式的需求。然而,算存失衡發展嚴重限制了算力利用效率,并帶來了巨大的算力資源損失,實際可用算力規模增速難以滿足應用發展需求。隨著集群規模從千卡向萬卡發展,跨尺度、多層次互聯技術將成為未來集群性能擴展效率的關鍵。在算力和電力資源的雙重限制下,大模型軍備競賽正在向效率之爭快速轉變,亟需圍繞算力生產、聚合、調度、釋放四大環節構建高算效實現的完整技術體系,從集群設計和數據中心部署層面實現更高能效,最終形成可持續、可獲得、可評估的高質量算力。
來源:信息通信技術與政策



